[1]:
import straxen
import matplotlib.pyplot as plt
2026-07-08 01:28:57,240 - admix - WARNING - Initializing utilix DB failed. You cannot do database operations
DB initialization failed
Tutorial SCADA-Python
In this notebook we show the basic functionalities of our SCADA interface. As a first step we have to initialize the interface. Please note that this is only possible for XENON members who are working on Midway. The straxen client will request a security token from our slowcontrol webservice. This token is only valid 3 hrs.
[2]:
sc = straxen.SCADAInterface()
/home/dwenz/mymodules/utilix/utilix/mongo_storage.py:428: DownloadWarning: Downloading PMTmap_SCADA.json to ./resource_cache/694d47e7cf82ecd0f80b11bed94acbb9
warn(f"Downloading {config_name} to {destination_path}", DownloadWarning)
Received token, the token is valid for 3 hrs.
from 08.07. 06:29:12 UTC
till 08.07. 09:29:12 UTC
We will automatically refresh the token for you :). Have a nice day and a fruitful analysis!
After getting the token we can query some parameters. Lets try to get some data for a certain time range and set of different parameters. The parameters can be specified via a dictionary which takes as values the Historian database names of the required parameter and some short name as key. Let us query as an example some different parameters:
[3]:
parameters = {
"para1": "XE1T.CTPC.Board06.Chan011.VMon",
"para2": "XE1T.CRY_TE101_TCRYOBOTT_AI.PI",
"para3": "XE1T.CRY_PT101_PCHAMBER_AI.PI",
"para4": "XE1T.GEN_CE911_SLM1_HMON.PI",
"para5": "XE1T.CRY_FCV104FMON.PI",
}
Feel free to give in your own analysis more meaningful parameter keys. Since it can be quite annoying to look up all those parameter names we also offer some functions which can return the corresponding names. For example for our PMTs the following function returns the high-voltage and current names:
[4]:
pmts = sc.find_pmt_names(range(10, 12), hv=True, current=True)
pmts
[4]:
{'PMT10_HV': 'XE1T.CTPC.BOARD03.CHAN008.VMON',
'PMT10_I': 'XE1T.CTPC.BOARD03.CHAN008.IMON',
'PMT11_HV': 'XE1T.CTPC.BOARD04.CHAN002.VMON',
'PMT11_I': 'XE1T.CTPC.BOARD04.CHAN002.IMON'}
Beside the parameters we also have to specify the time range we would like to query. Since straxen handles time intervals in unix time nano-seconds it is natural to do the same here (Do not worry we can also query times in a human readable way which is shown below).
[5]:
start = 1709682275000000000
end = 1709736527000000000
df = sc.get_scada_values(parameters, start=start, end=end, every_nth_value=1)
As the name already suggest the data is returned as a simple data DataFrame:
[6]:
df.head()
[6]:
| para1 | para2 | para3 | para4 | para5 | |
|---|---|---|---|---|---|
| time UTC | |||||
| 2024-03-05 23:44:35+00:00 | 1211.0 | -94.566826 | 2.041337 | -1.1 | 3.572651 |
| 2024-03-05 23:44:36+00:00 | 1211.0 | -94.564354 | 2.041424 | -1.1 | 3.572651 |
| 2024-03-05 23:44:37+00:00 | 1211.0 | -94.559937 | 2.041635 | -1.1 | 3.572651 |
| 2024-03-05 23:44:38+00:00 | 1211.0 | -94.554665 | 2.041380 | -1.1 | 3.572651 |
| 2024-03-05 23:44:39+00:00 | 1211.0 | -94.551048 | 2.041904 | -1.1 | 3.572651 |
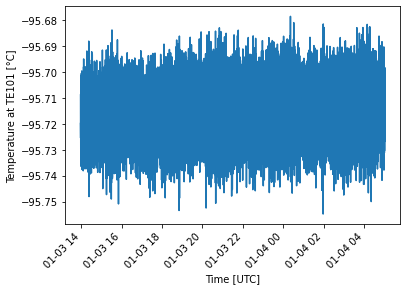
[7]:
plt.plot(df["para2"])
plt.xlabel("Time [UTC]")
plt.ylabel("Temperature at TE101 [°C]")
plt.xticks(rotation=45, horizontalalignment="right")
plt.show()
Querying data in a human readable way:
Querying data with timestamps in nano-seconds unix times can be a bit tedious, especially, if you are not working with any straxen data. In order to allow a query in a human readable way we added some widgets:
[8]:
tw = straxen.TimeWidgets()
After initialization you can render the widgets via…
[9]:
tw.create_widgets()
[9]:
… and select any time range you would like. After specifying a time you can get the start and end time via:
[10]:
start, end = tw.get_start_end()
print(start, end)
1783481340000000000 1783484940000000000
In addition to this time widget we also offer analyst to query data via run_ids. This can be quite handy if you would like to correlate your data with other detector parameters. Further, you can also query data with a coarser binning e.g. every 300 seconds. Before we can use run_ids though we have to specify the context we are working with:
[11]:
st = straxen.contexts.xenonnt_online()
sc.context = st
Provides of multi-output plugins overlap, deregister old plugins <class 'straxen.plugins.merged_s2s.merged_s2s.MergedS2s'>.
You specified _auto_append_rucio_local=True and you are not on dali compute nodes, so we will add the following rucio local path: /project/lgrandi/rucio/
[12]:
df = sc.get_scada_values(parameters, run_id="055000", every_nth_value=10)
Changing the time zone
You can also easily change the timezone of your data if needed:
[13]:
dfcet = straxen.convert_time_zone(df, "CET")
dfcet.head()
[13]:
| para1 | para2 | para3 | para4 | para5 | |
|---|---|---|---|---|---|
| time CET | |||||
| 2023-10-25 11:28:23+02:00 | 1211.099976 | -94.659271 | 2.025028 | -1.1 | 6.946674 |
| 2023-10-25 11:28:33+02:00 | 1211.099976 | -94.656357 | 2.025173 | -1.1 | 6.946674 |
| 2023-10-25 11:28:43+02:00 | 1211.099976 | -94.658508 | 2.024580 | -1.1 | 7.056014 |
| 2023-10-25 11:28:53+02:00 | 1211.099976 | -94.669533 | 2.024475 | -1.1 | 7.056014 |
| 2023-10-25 11:29:03+02:00 | 1211.099976 | -94.666206 | 2.024703 | -1.1 | 7.242345 |
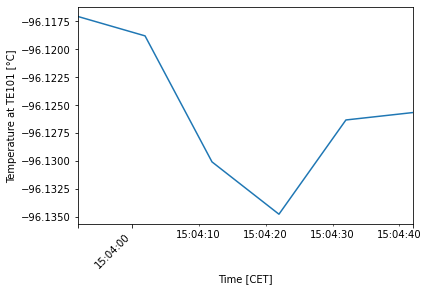
[14]:
dfcet["para2"].plot()
plt.xlabel("Time [CET]")
plt.ylabel("Temperature at TE101 [°C]")
plt.xticks(rotation=45, horizontalalignment="right")
plt.show()
[ ]: